error squiggly red underline off-by-one in parser
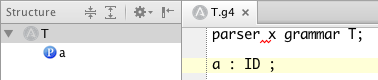
Well, i'm back to building the ANTLR v4 plugin. Works great! Until, that is, I give it a bad token or syntax error. I have turned off highlighting to simplify, so just 1 lexer. The issue is that the squiggly red underline is on the space before the x and not the x in the following sample input with bogus extraneous x token:
parser x grammar T;
a : ID;
And here is the set of tokens created by Lexer.getTokenType():
getTokenType: PARSER from [@-1,0:5='parser',<14>,1:0]
getTokenType: WS from [@-1,6:6=' ',<50>,1:6]
getTokenType: RULE_REF from [@-1,7:7='x',<2>,1:7] <-- bogus token at correct position
getTokenType: WS from [@-1,8:8=' ',<50>,1:8]
getTokenType: GRAMMAR from [@-1,9:15='grammar',<15>,1:9]
getTokenType: WS from [@-1,16:16=' ',<50>,1:16]
getTokenType: TOKEN_REF from [@-1,17:17='T',<1>,1:17]
getTokenType: SEMI from [@-1,18:18=';',<28>,1:18]
getTokenType: WS from [@-1,19:20='\n\n',<50>,1:19]
getTokenType: RULE_REF from [@-1,21:21='a',<2>,3:0]
getTokenType: WS from [@-1,22:22=' ',<50>,3:1]
getTokenType: COLON from [@-1,23:23=':',<25>,3:2]
getTokenType: WS from [@-1,24:24=' ',<50>,3:3]
getTokenType: TOKEN_REF from [@-1,25:26='ID',<1>,3:4]
getTokenType: WS from [@-1,27:27=' ',<50>,3:6]
getTokenType: SEMI from [@-1,28:28=';',<28>,3:7]
getTokenType: null from [@-1,29:28='<EOF>',<-1>,3:8]
That looks perfect, right? ANTLR even gives the correct msg:
extraneous input 'x' expecting 'grammar'
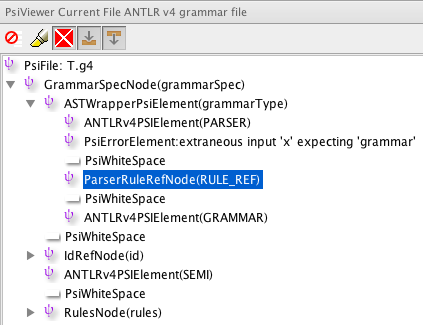
That appears upon start up of new IDEA and after editing file. Can anyone give me a pointer where to look in source to find this issue? I have verified that Lexer.getTokenStart() returns index 7 for x, which is correct. Enclosed screenshots including PSI tree. Is the error node in PSI tree causing off by one maybe?
Thanks!
Terence
Attachment(s):
psi-off-by-one.png
{kind=link}
off-by-one.png
{kind=link}
Please sign in to leave a comment.
I've checked the plugin sources on github. Not sure (I haven't run them) but..
PsiErrorElements are created when PsiBuilder.error() or PsiBuilder.Marker.error() methods are used. The difference is that PsiBuilder.error() always produces zero-length error in the current position. I see only one error() call in org.antlr.intellij.plugin.adaptors.ParserErrorAdaptor#syntaxError and it is the one of PsiBuilder.
In order to create parsing errors (PsiErrorElements are almost ordinary PSI elements that automatically get red waves highlighting) that span several tokens one shall use PsiBuilder.Marker#error():
Another strange thing is 2 missing PsiWhitespaces near the error on the PSI Viewer screenshot.
BTW Please provide PSI Viewer screenshots using our built-in PSI Viewer (Tools/View PSI Structure) with Whitespaces and Tree Nodes modes ON.
Hi. The problem is that I need to announce an error at a token and continue in that same rule function. In other words, if I am parsing tokens for rule declaration, I don't want to bail out of that associated parsing function just because I find an extraneous token. I want to create a standard declaration-rooted tree with an error node indicating the invalid token. Unfortunately, it appears that marker.error() closes the current mark().
I can't find any document summarizing error handling; I'm learning just by looking at handbuilt parsers in plug-ins that I see.
The "missing" white space tokens appear after the error node. You should see WS RULE_REF WS where RULE_REF is the bogus token.
In the final analysis, I just need to label tokens that appear in the PSI as erroneous or extraneous. That is a much finer level than throwing away an entire subtree just because of a bad token. Is there a way to label tokens or must I throw out the enclosing rule reference? Right now, it almost highlights the correct token, which is much better than marking the entire construct as invalid. I also believe that I have white space entry node modes on; otherwise it wouldn't show the white space right?
Thanks,
Ter
You can always create new marker before the token, advance lexer and then close it via error(..) call thus keeping the "rule marker" intact.
I don't know any other way on the parser level.
oh! great idea! I'll try. The biggest problem is that WS is not sent to my parser and so it will likely always be out of sync, right? The error is detected before I have consumed the invalid token (using lookahead in the ANTLR parser). I might have to get tricky by advance()ing until I see the offending token.
Ter
[update] works better but not perfectly even w/o getting tricky.
You can get WS into the parser by returning empty TokenSet in your ParserDefinition#getWhitespaceTokens() (same applies to comments).
Even when WS are skipped it is possible to use PsiBuilder#rawXXXX methods to handle specific cases.
thanks. i'll try that.
T