DEDENT tokens problem
Hi.
I'm writing custom language plugin and my language uses Python-like indentation for blocks.
I use LookAheadLexer to handle indentation.
The problem is that lexer tokens should cover some chunk of source code. For example, if I have:
line1
line2
line3
line4
There are spaces to be associated with INDENT tokens. Like: line1, CRLF, INDENT, line2, CRLF, INDENT, INDENT, line3, CRLF, line4.
But there is no room to associate DEDENT tokens with, and PSI structure I actually need is line1, CRLF, INDENT, line2, CRLF, INDENT, INDENT, line3, CRLF, DEDENT, DEDENT, line4.
When I try to use addToken(DEDENT) in my lookAhead method it doesn't work (I either try to cover an empty range of text or some range that is already covered by another token).
How should INDENTs and DEDENTs be handled exactly?
Please sign in to leave a comment.
Tokens are not required to have a non-zero length. You can look at the implementation of the Python lexer: https://github.com/JetBrains/intellij-community/blob/master/python/src/com/jetbrains/python/lexer/PythonIndentingProcessor.java
But is there a way to add zero-length DEDENT tokens from lookAhead method of LookAheadLexer descendant? Otherwise, I wonder if there is a documentation describing how MergingLexerAdapter works?
I'm trying to figure it out, I've decided to set up a smallest example possible to get understanding.
My lexer extends MergingLexerAdapter, I've taken getTokenType, getTokenStart and getTokenEnd methods from your Python example.
My advance method looks like:
if (myTokenQueue.size() > 0) {
myTokenQueue.remove(0);
} else {
super.advance();
if (getTokenType() == MyTypes.CRLF) {
int pos = super.getTokenEnd();
myTokenQueue.add(new PendingToken(MyTypes.DEDENT, pos, pos));
}
}
And it doesn't work. I don't see DEDENT tokens in PSI viewer and when I begin to edit something, it appears to be buggy. Everything works ok without myTokenQueue.add(new PendingToken(MyTypes.DEDENT, pos, pos));
It looks like I am getting this wrong at some point. I just wonder what this point is.
First of all, it doesn't matter for you whether your lexer extends MergingLexerAdapter or not. PythonIndentingProcessor does that for reasons unrelated to indent handling, and your code will work just as well if you extend LexerBase.
Second, you won't see indent tokens in the PSI viewer. The correct way to check if your lexer works is to write a test (see PythonLexerTest for an example).
Also, the highlighting lexer works incrementally, and it's not easy to support proper handling of indents in an incremental lexer. Python uses different lexers for highlighting and for parsing; the lexer used for highligthing (PythonHighlightingLexer) does not include any handling of indents.
Damn. I'm getting it now. Two lexers thing should be written with a huge letters from the beginning :(. Along with inability to see zero-length tokens in PSI viewer.
What doesn't work when adding empty tokens to LookAheadLexer? What do you observe?
I tried to insert zero-length INDENT token after every CRLF, just for testing.
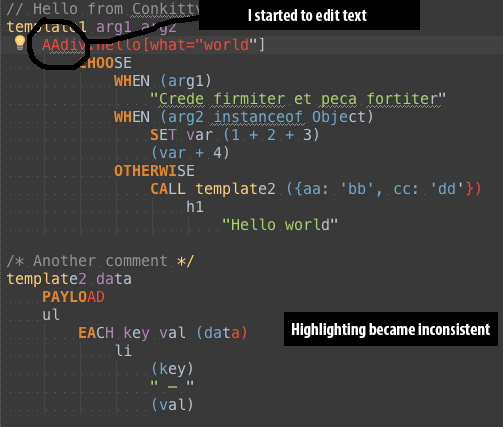
Not only I don't see INDENT tokens in PSI viewer, but also highlighting become inconsistent when I start to edit the code.
Below are a couple of screenshots.
Initial state:
Then I start to edit the code:
Do you add DEDENT as the first token in lookAhead method, somewhere in the middle, or the last one?
I tried something like this in lookAhead:
IElementType type = baseLexer.getTokenType();
if (type == MyTypes.CRLF) {
int pos = baseLexer.getTokenEnd();
addToken(type);
baseLexer.advance();
addToken(pos, MyTypes.INDENT);
type = baseLexer.getTokenType();
}
advanceAs(baseLexer, type);
And I've posted a bit of code from another try I've made (descending from MergingLexerAdapter), and it produces the same visual result.
It appears that your lexer is restarted from INDENT token position and it doesn't know from the offset only whether it should include IDENT or not. Could you please trace how "start" method is called, which start offsets are passed into it, and which initialState is supplied (should be always 0 actually). Please also check that your lexer actually was in the same state as initialState at that offset during previous lexing of the same file.