Completion Contributor: Changed dummy indentifier received by other contributors

Hi,
I am trying to implement a completion contributor for a custom language using an ANTLR parser.
I added two completion contributors and one of them changes the injected dummy identifier because the ANTLR error recovery is very hard to control. Thats why injecting a valid element according to the context instead of just injection the default dummy is easier (different problem I don't want to target here). The result of just changing the dummy identifier is that the other completion contributor fails because he also receives the changed dummy. Is this the expected behaviour or is something wrong with my implementation? I would rather expect that each contributor receives his "own" dummy identifier and the parser parses the text with those different dummy identifiers multiple times.
So my final question is: How do I avoid injecting a dummy at all (to avoid possible errors) without affecting other contributors so that I just need to check the current context of my carret (e.g. using element patters)?
Please sign in to leave a comment.
Hi David,
Could you please provide us with more context?
How do you change the dummy identifier?
Why identifier breaks the code and what kind of element does your completion provider complete?
Hi Karol,
I am trying to implement keyword completion based on the context of my current caret position.
According to the Java doc in the com.intellij.codeInsight.completion.CompletionContributor class this method is used to change the dummy:
So thats where I am changing the dummy by using the setter of the given context. As I already mentioned this also changes the dummy for all other contributors so I build an if clause around the setter to check the context of my caret like this:
override fun beforeCompletion(context: CompletionInitializationContext) {
val ctx = context.file.findElementAt(context.startOffset)
if (ctx?.parent?.parent is VB6ModuleBody
|| ctx?.parent?.prevSibling is VB6ModuleBody
|| (ctx?.parent?.prevSibling is VB6ModuleDeclarations && ctx.parent?.nextSibling is VB6ModuleBody)) {
context.dummyIdentifier = "Public Sub dummy\n End Sub" // <--- valid in the context
}
}
I know that it would be better to use element patters in this case but for now this is okay.
After changing the dummy the file seems to be parsed again with the dummy, which should lead to valid parse tree according to the language (if my context check works) but to make sure I check this again inisde the fillCompletionVariants Method of the contributor.
Inserting an identifier would look like this:
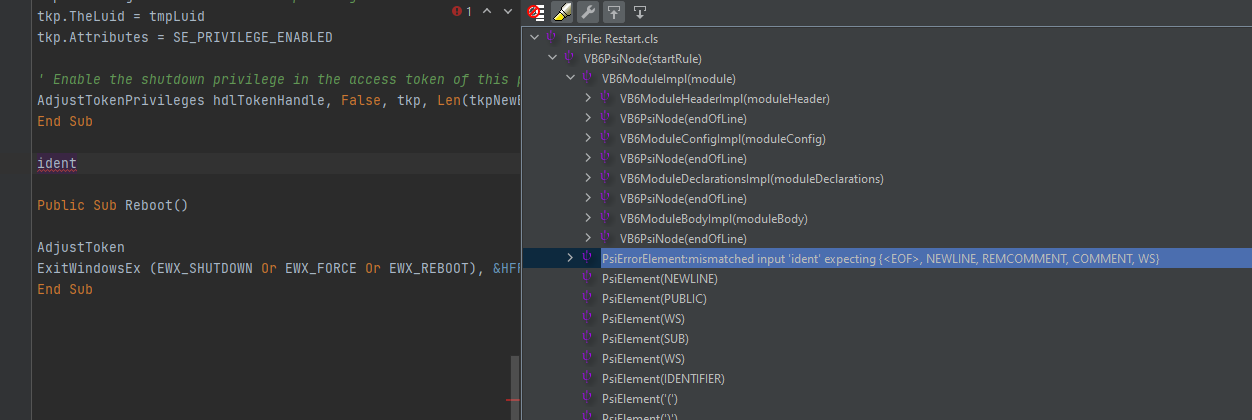 As you can see the identifier "ident" between those two subroutines leads to an PsiErrorElement and the parser fails to parse the following elements. Now the context of my inserted dummy is the "startRule" and not as expected the "moduleBody" rule. In a GrammarKit parser I would do something like consume all tokens until the parser reaches an end of line but implementing this for an ANTLR parser this is much more difficult.
As you can see the identifier "ident" between those two subroutines leads to an PsiErrorElement and the parser fails to parse the following elements. Now the context of my inserted dummy is the "startRule" and not as expected the "moduleBody" rule. In a GrammarKit parser I would do something like consume all tokens until the parser reaches an end of line but implementing this for an ANTLR parser this is much more difficult.
Beside of this problem, I still dont understand why I should insert a random dummy at any position and then parse it. This does not make sense to me as it fails in the most cases.
This is why I am asking how to implement completion only based on the current caret context. In my case without inserting a dummy. Including not changing the shared mutable state of the it.
Hi David,
Thank you for the clarification.
The dummy identifier is inserted to have any completion context, and for most languages, this is the correct approach, because most completions are intended to complete identifiers. When you use setDummyIdentifier(), as you observed it is done on the shared context used by all contributors invoked in a given completion and you can't change this behavior. All completion contributors' beforeCompletion() methods are executed at once before completion, so all contributors will get the same identifier during completion.
I don't understand why your second contributor doesn't have this problem, because the context is exactly the same, so the default dummy identifier would break the PSI the same way or I'm missing something?
Consider using an empty dummy identifier. Maybe it will be suitable for both contributors. Also, take a look at the topics related to completions using ANTLR parsers:
Hi Karol,
If most completions are intended to complete identifiers I can understand it. At least to a certain degree because when I do not want to do complete an identifier I need a complex workaround for a very simple problem (e.g. changing the shared context). Or is there any better solution for providing keyword completion that I did not found yet?
The reason why it does not break the other contributor is because the other contributor does reference based completion so inserting the identifier dummy is valid in this case.
An empty dummy could help in this situation thats right. For my reference completion this would also work I guess.
The links contain useful informations. Thank you for that.